← Kryven Research
May 22, 2026 · Kryven Research · Cost: $15 · EMPIRICAL
Training Per-Token MLA Latent Gating Networks: A Hyperparameter Recipe and Failure-Mode Taxonomy
A 1.3M-parameter gating network on the rank-512 MLA latent of DeepSeek-V2-Lite trains only under a corrected hyperparameter recipe. The DeepSeek-V3 Load-Free Balancing control-gain default is roughly 30× too weak when transposed from expert-routing onto a per-token gating problem, and produces a previously-uncharacterized R-collapse-to-one failure mode where the gate learns to never evict. The full empirical budget across the training-recipe runs reported here was ~$15 of GPU time.
Status — interim publication. This post documents the training recipe and failure-mode taxonomy stage of an active project. The adversarial information-bottleneck evaluation that would adjudicate whether the trained gate beats a no-eviction baseline at matched quality is running separately and has not yet returned; this is what we can publish now. The "headline numbers" below are the recipe's training-side equilibrium properties, not a quality verdict against alternatives.
Mechanism
R is a small (~1.3M-parameter) per-token network sitting on the rank-512 MLA latent of DeepSeek-V2-Lite-16B. It produces a continuous score per token that drives a probabilistic eviction decision: at a target eviction rate of 40%, tokens with the lowest R-scores leave the KV cache during a periodic compaction step. A class-bias scalar b_class is updated by a DeepSeek-V3-style Load-Free Balancing (LFB) control loop, nudging the realized eviction rate back toward the target.
Prior art
The structural novelty of this class of mechanism is gone:
DeepSeek V3.2-Exp (September 29, 2025) ships DeepSeek Sparse Attention — sparse selection over the attention surface, validated at production scale. EG-MLA (arXiv:2509.16686, September 2025) introduces token-specific embedding gating in the latent space, with task-loss-only training. CapKV (arXiv:2604.25975) frames KV eviction as information-bottleneck capacity maximization. Our contribution is not the mechanism — it is the training recipe and failure-mode characterization that the public literature does not yet document.
The failure: R collapses to "never evict"
Our first nine attempts used the DeepSeek-V3 LFB defaults transposed directly: β₀ = 5.0, γ = 0.001. Run after run, R drifted toward a near-constant score, the class bias saturated, and the eviction rate collapsed to zero. The gate had learned to never evict, regardless of input. The variance of the per-token mask m_t collapsed below 0.01 within the first 200 steps and never recovered.
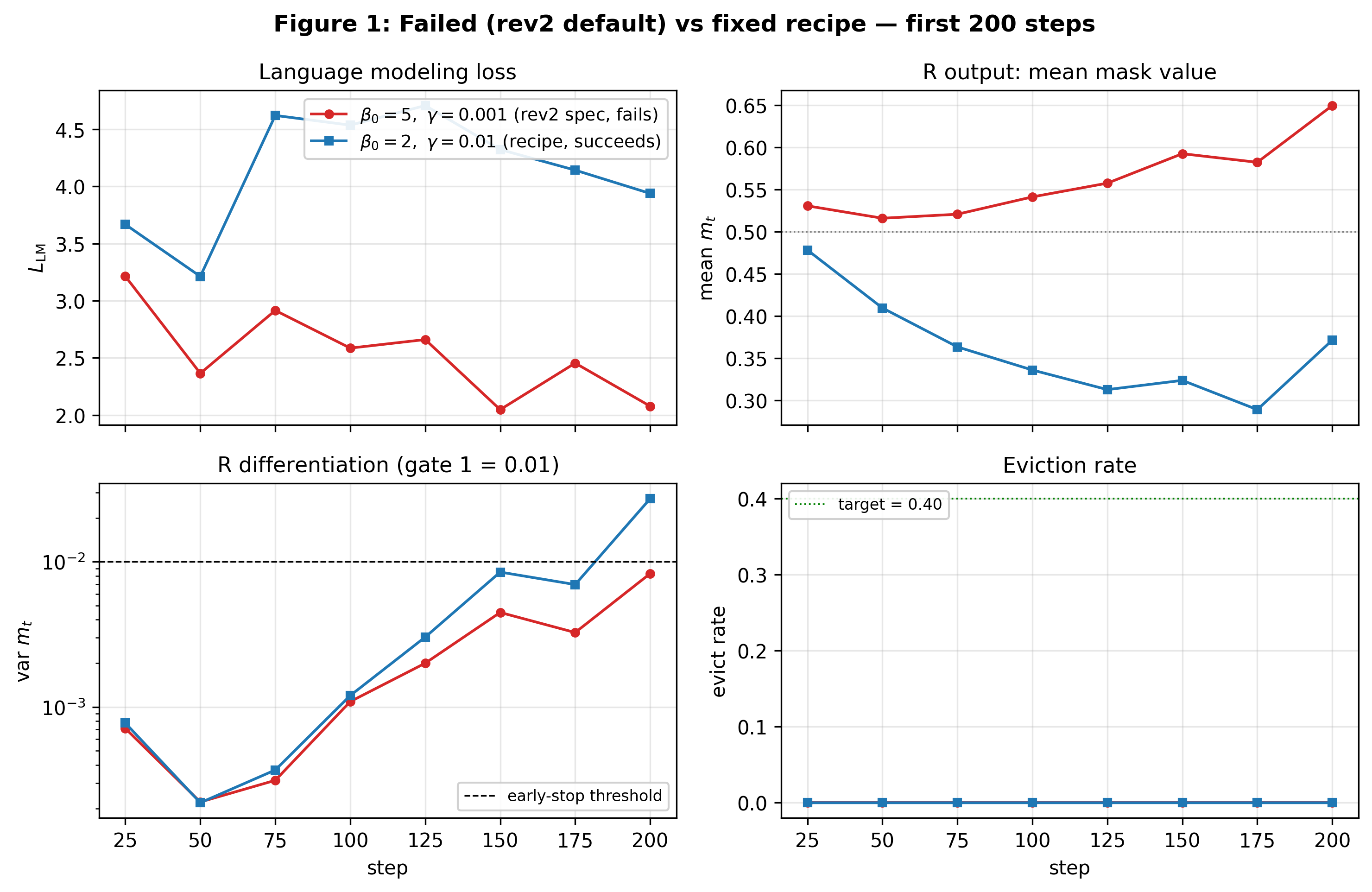
The collapse mode is new in the gating-network setting. The V3-style LFB literature describes routing-bias drift in MoE; it does not describe gating-network collapse on a continuous latent. Naming and characterizing it is half of this post.
The calibration argument
The DeepSeek-V3 LFB defaults break here for a specific structural reason:
The DeepSeek-V3 LFB bias is calibrated for expert routing, where a per-expert bias adjusts a routing decision over N_experts candidates. Each expert sees a sparse subset of tokens, so the per-expert logit shifts are small per step.
Our setting is structurally different: R is a trainable network with 1.3M parameters that produces a logit for every token. The per-step logit drift induced by R's gradient updates is at the standard NN-training scale (10⁻³ in our setup), comparable to expert routing's full-magnitude shifts. The control gain γ must scale to match this drift rate — empirically, by ~30× relative to V3.
This is not a mechanism failure; it's a control-system-authority failure that the V3 default mis-calibrates by orders of magnitude when transferred.
The corrected recipe: β₀ = 2.0, γ = 0.01 — γ raised by 10× and β₀ halved to suppress initial logit saturation. The proposed calibration rule, derivable from the same argument and estimable from a 50-step diagnostic run prior to full training:
γ ≳ 3 · 𝔼[‖Δlogit_R‖₁ / step]
Headline numbers
| Run |
β₀ |
γ |
Result at step 200–300 |
| Attempt 9 (rev2 spec defaults) |
5.0 |
0.001 |
Early-stopped at step 200; var(m_t)=0.0083, mean(m_t)=0.65, eviction rate = 0 throughout. R collapsed to "never evict." |
| Attempt 10 (corrected recipe) |
2.0 |
0.01 |
R differentiates by step 250 (var=0.0295, evict=0.172); by step 300, evict=0.48, slightly overshooting the 0.40 target before equilibrating. |
| Attempt 11 (seeds 0 and 1, same recipe) |
2.0 |
0.01 |
At step 300, evict rates 0.478, 0.483, 0.487 across seeds 42/0/1 — within 5×10⁻³. var(m_t) at step 325 within 10⁻⁴ across all three seeds. |
Three-seed reproducibility
The Attempt-10 recipe is visually indistinguishable across three independent seeds and exhibits a clean control-loop signature: b_class drifts opposite the eviction-rate error with the expected lag.
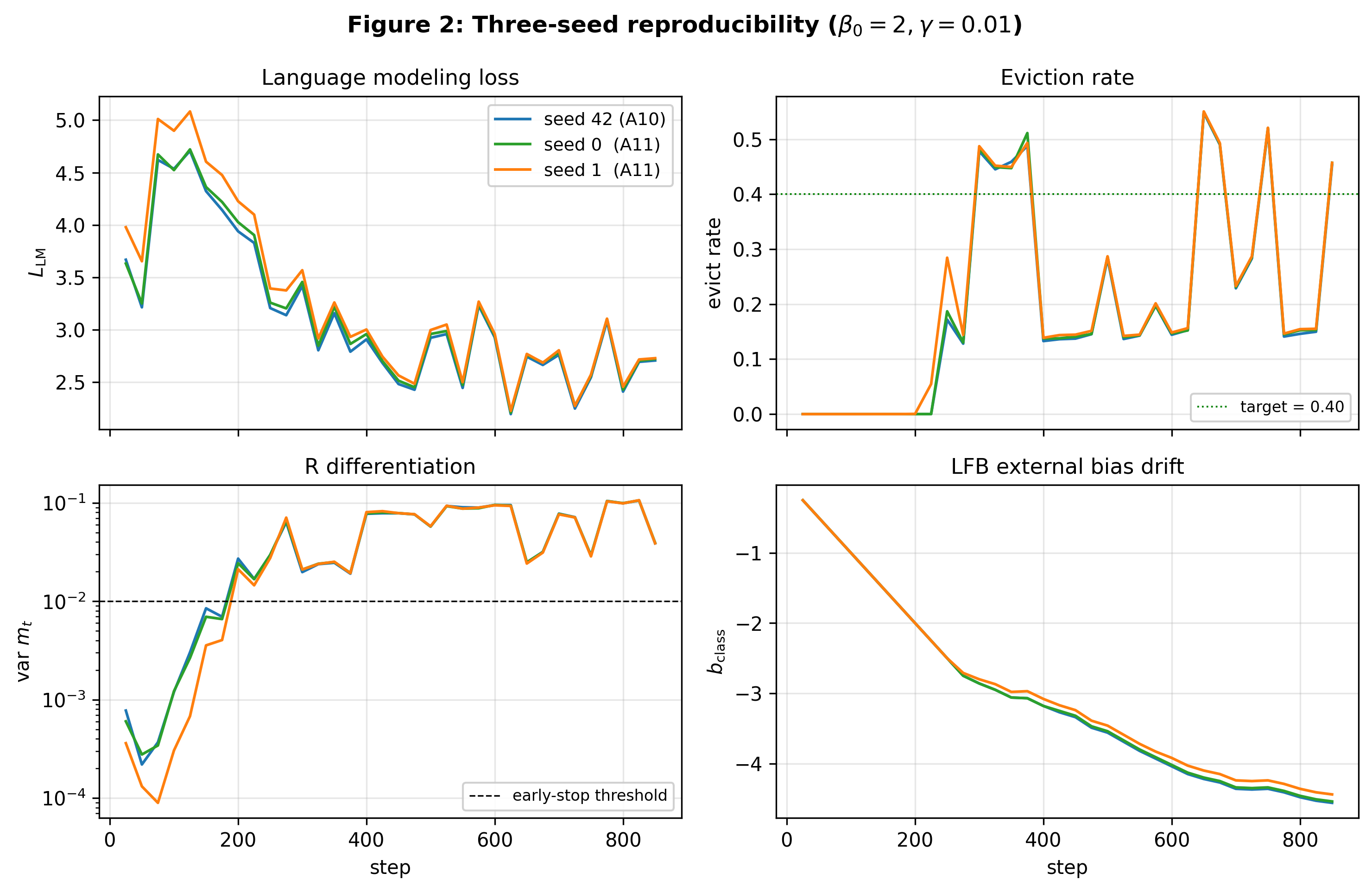
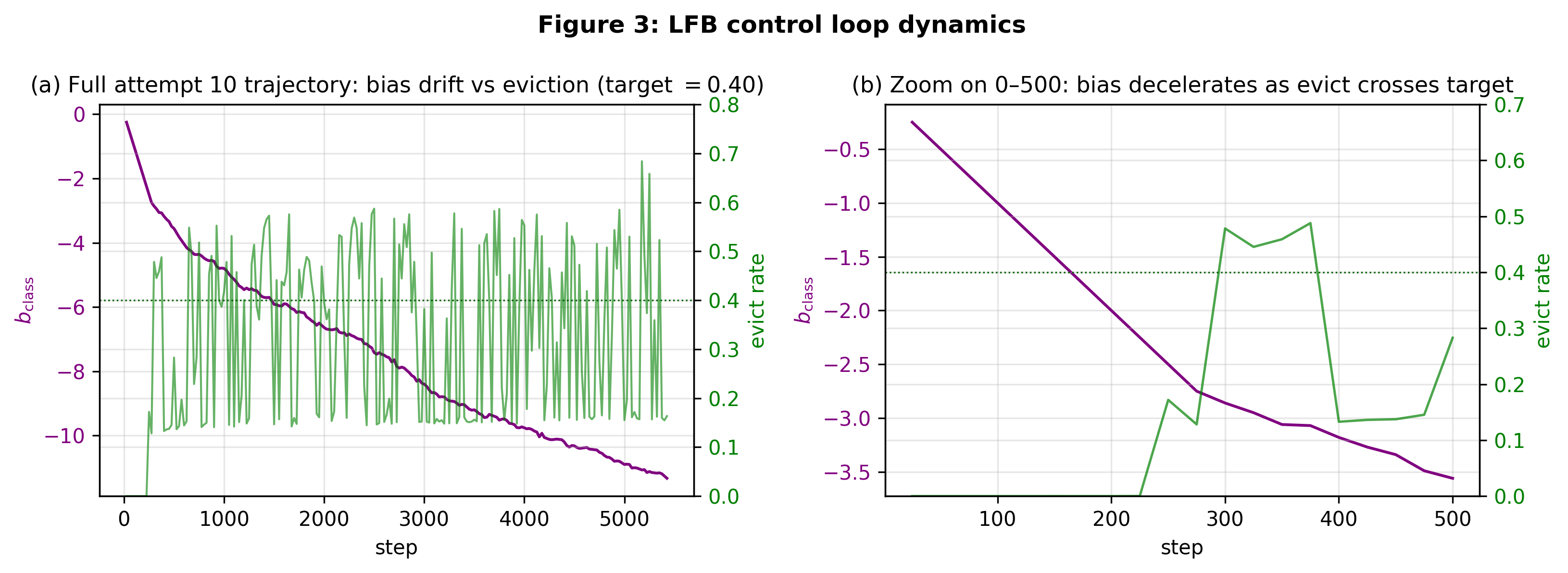
Long-run dynamics
A 5,425-step run at the corrected recipe holds together. L_LM drops from 3.67 to 1.45. Eviction oscillates between roughly 0.13 and 0.55 around the 0.40 target with a 50–100-step period — the equilibrium signature of a control loop with non-trivial dead-time, not a drift toward either failure mode. var(m_t) stays in [0.02, 0.12], well above the 0.01 collapse threshold throughout. No late-run drift toward either R-collapse or to a degenerate constant.
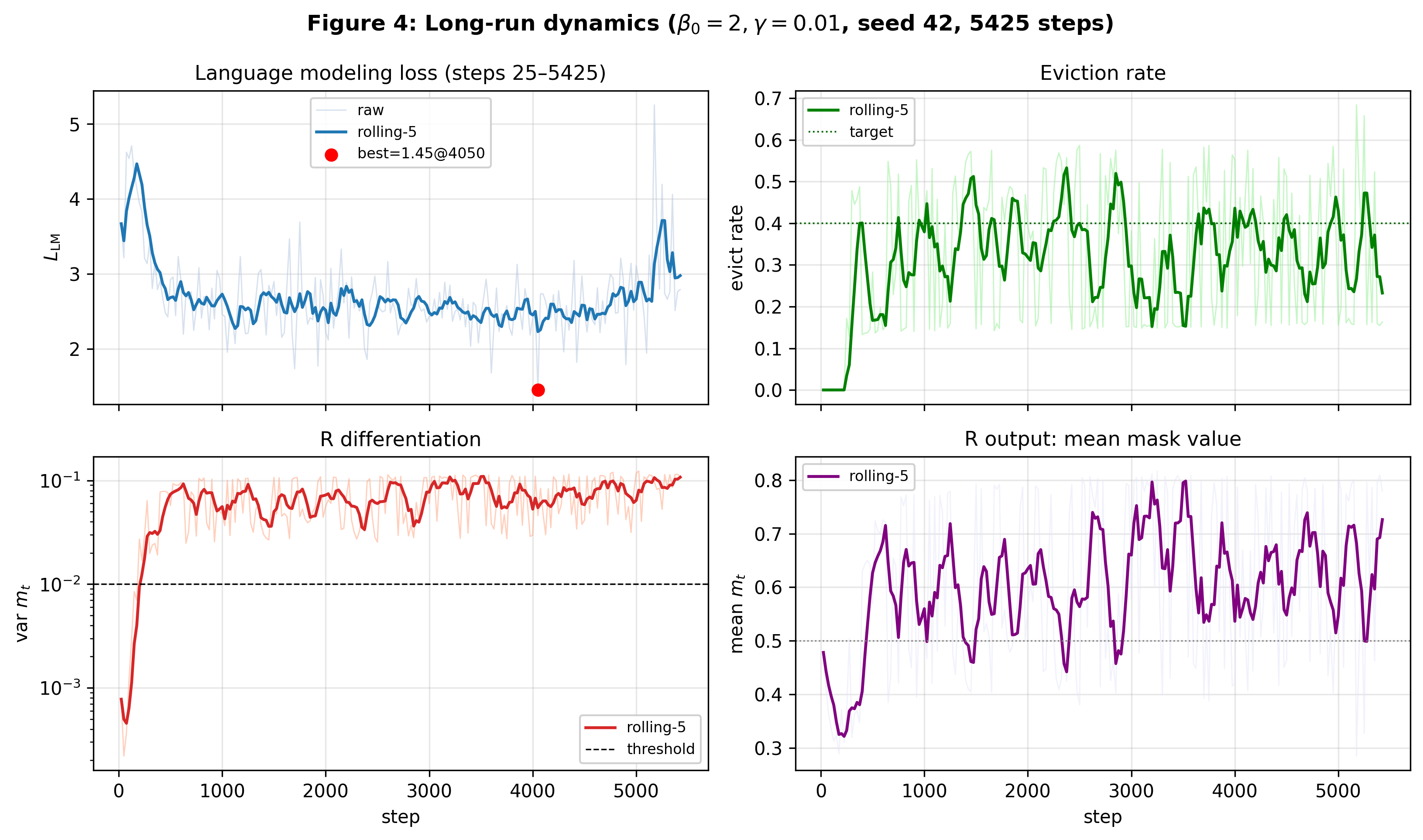
Caveats
What we can and cannot claim, verbatim:
- No baseline comparison. No vanilla V2-Lite-LoRA (no eviction), no random-40% eviction, no attention-score-based eviction (e.g., ChunkKV) at matched compute. The strongest claim we can support is "the mechanism trains and the control loop equilibrates." We cannot yet say the mechanism is better than the alternatives.
- No inference benchmark. Actual KV-cache memory savings and tokens/sec at 40% eviction relative to the no-eviction baseline are unmeasured. The deployment-relevant numbers are unknown.
- seq_len = 4K, not 32K. A6000 VRAM constraint; the long-context claim is unsupported.
- Partial inter-seed independence. The streaming dataset iterator is not seed-controlled; observed cross-seed reproducibility is partly explained by shared sample order.
- Single substrate. Only V2-Lite-16B. Cross-architecture generalization (Qwen, Llama with similar gating heads) is not tested.
What's next
Three things are missing and are concrete next steps: (a) a baseline comparison against vanilla V2-Lite-LoRA, random-40% eviction, and at least one attention-score-based eviction at matched compute, on a fixed eval; (b) the deployment-relevant numbers — KV-cache memory and tokens/sec at 40% eviction; (c) cross-substrate transfer — a Qwen or Llama checkpoint with a structurally similar gating head, to see whether the γ-calibration argument is substrate-portable as the structural argument predicts.
The recipe is small, the methodology is auditable, and the empirical spend is on file. We are publishing it now because the public literature documents the mechanism (DeepSeek Sparse Attention, EG-MLA, CapKV) but does not yet document a training recipe for it; recipes ship paper-class mechanisms more reliably than another mechanism does.
← Back to Kryven Research